
RegEx, or Regular Expressions, is now in Excel! Regex functions simplify text manipulation, like search, match, clean, and extract text.
This article covers common regex syntax and explains how to enable and use it effectively in Excel for data cleaning. Through useful examples, we’ll discover three Regular Expression functions in Excel.
Table of contents:
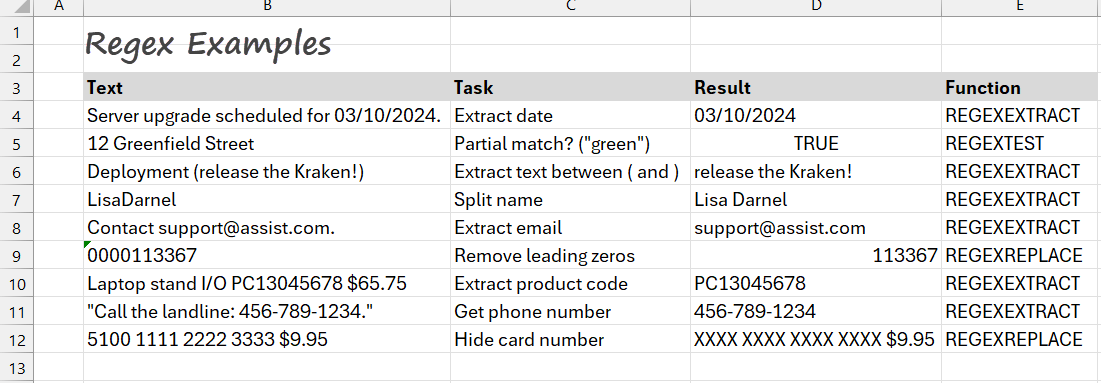
- What are Regular Expressions?
- RegexExtract
- RegexReplace
- RegexTest
- Excel Regex Function Examples
- Cheat Sheet: How to use Regular Expressions in Excel
- Regex Add-in for Excel
Can you imagine how useful it would be to standardize a list of email addresses in different formats? Or how about extracting dates from free-form text fields? Introducing: RegEx!
What is Regex? What are Regular Expressions?
Regular expressions, or “regex,” are special formulas for finding and modifying text. Regex uses patterns to match specific strings within the text. Their power and flexibility make them essential in tasks like searching, parsing, and replacing text across various programming languages, including Python, JavaScript, and Java.
With native regex support in Microsoft 365, Excel now offers three functions – REGEXEXTRACT, REGEXTEST, and REGEXREPLACE – that allow you to standardize formats, extract information, and clean large datasets directly in Excel with no extra software needed.
REGEXEXTRACT Function
The REGEXEXTRACT function extracts specific parts of the text that match a pattern you define. You provide the text or a cell reference containing the text you want to search, and then you specify the regular expression (regex) that describes the pattern of the text you want to extract. For example, you can use it in Excel to find URLs, postal codes, or specific keywords in a list.
Syntax:
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
Arguments:
- text: The cell or text from which you want to extract data. (Required).
- pattern: The regex pattern that defines what you want to extract. (Required)
- [return_mode]: Specifies how matches are returned.
- “0“: First match.
- “1“: All matches as an array.
- “2”: Parts of the first match (captured groups) as an array.
- [case_sensitivity]: Defines if matching is case-sensitive.
- “0“: Case sensitive.
- “1“: Case insensitive.
REGEXREPLACE Function
The REGEXREPLACE function replaces strings within the provided text that matches the pattern with replacement. This functionality is helpful for several reasons. For example, it can automate correcting common errors or formatting issues in data. From now on, it is easy to fix date formats, standardize phone numbers, or correct misspelled words.
Syntax:
REGEXREPLACE(text, pattern, replacement, [occurrence], [case_sensitivity])
Arguments:
- text: The text or cell to be modified. (Required)
- pattern: The regex pattern to identify what to replace. (Required)
- replacement: The new text to insert in place of the pattern. (Required)
- occurrence: Specifies which match to replace (0 = all, negative values count from the end).
- case_sensitivity: Defines case sensitivity (0 = sensitive, 1 = insensitive).
REGEXTEST Function
The REGEXTEST function allows you to check whether any part of the supplied text matches a regular expression (“regex”). It will return TRUE if there is a match and FALSE if not.
The REGEXTEST function is my personal favorite. It offers quick and straightforward solutions to many problems that were previously difficult to solve. This includes writing formulas like “if cell contains”. Checking these used to be a cumbersome task. I emphasize, used to be…
Syntax:
REGEXTEST(text, pattern, [case_sensitivity])
Arguments:
- text: The text or the reference to a cell containing the text you want to match against.
- pattern: The regular expression describes the text pattern you want to match.
- case_sensitivity: Determines whether the match is case-sensitive. By default, the match is case-sensitive.
- “0“: Case sensitive.
- “1“: Case insensitive.
Excel Regex Function Examples
In this section, we will explore various examples of how to use regular expressions (regex) in Excel to extract specific data patterns from text. These examples demonstrate practical applications of regex formulas, such as identifying and extracting dates, numbers, or other structured data from within text strings.
Example 1: Extract dates from a cell containing text
In the first example, I want to extract all dates from a cell that contains various text using an Excel regex formula.
The formula looks like this:
=TOROW(REGEXEXTRACT(B3,”(\d{2}/\d{2}/\d{4})”,1))
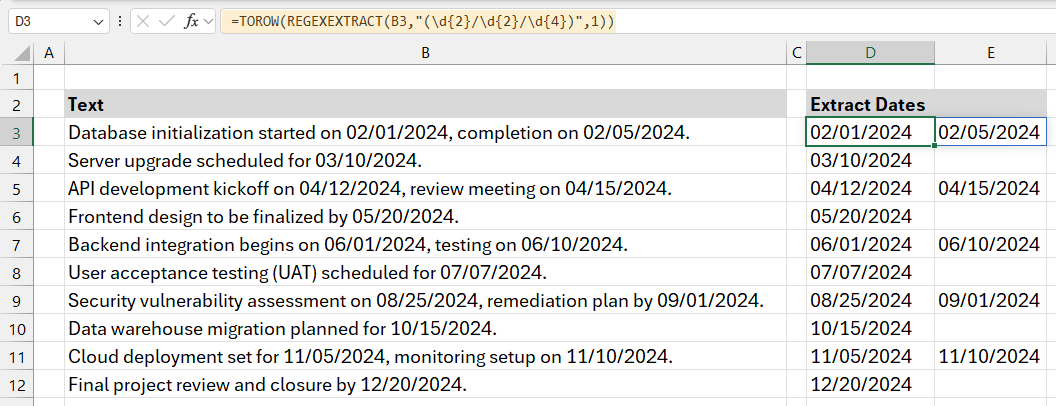
Explanation: Here’s a breakdown of each component in the Excel regex formula:
- Function: REGEXEXTRACT finds and extracts text that matches a specific pattern.
- Target Cell (B3): The function scans B3 for sequences matching the pattern.
- Regular Expression (“(\d{2}/\d{2}/\d{4})”):
- \d: matches any digit (0-9).
- {2}: ensures two digits in a row (e.g., day and month).
- /: is the literal slash separator.
- \d{4}: matches exactly four digits (year).
- The overall pattern matches dates in the DD/MM/YYYY format.
- Return Mode (1): Extracts all date matches in an array.
The TOROW function in the formula =TOROW(REGEXTRACT(B3, “(\d{2}/\d{2}/\d{4})”),1) is used to ensure that the extracted data from the REGEXTRACT function is transformed into a single row. When REGEXTRACT extracts multiple date values from a single cell, it can return them as an array (a collection of values). The TOROW function ensures that all extracted date values are placed in a single row, making the data easier to manage and view.
Example 2: IF Cell contains specific text
in this example, the goal is to check if a cell contains specific text. We’ll use the REGEXTEST function. The search string is “green”.
The first argument is the cell you want to check. Next, add the regex pattern you want to check. The third argument of the REGEXTEST function is case sensitivity. I’m using a non-case-sensitive search in the example, so type 1. If you want a case-sensitive test, use 0 as a third argument.
Non-case sensitive matches:
=IF(REGEXTEST(B3,”green”,1),”Found”,”Not found”) //partial match
=IF(REGEXTEST(B3,”\bgreen\b”,1),”Found”,”Not found”) //exact match
Case-sensitive matches:
=IF(REGEXTEST(B3,”green”,0),”Found”,”Not found”) //partial match
=IF(REGEXTEST(B3,”\bgreen\b”,0),”Found”,”Not found”) //exact match
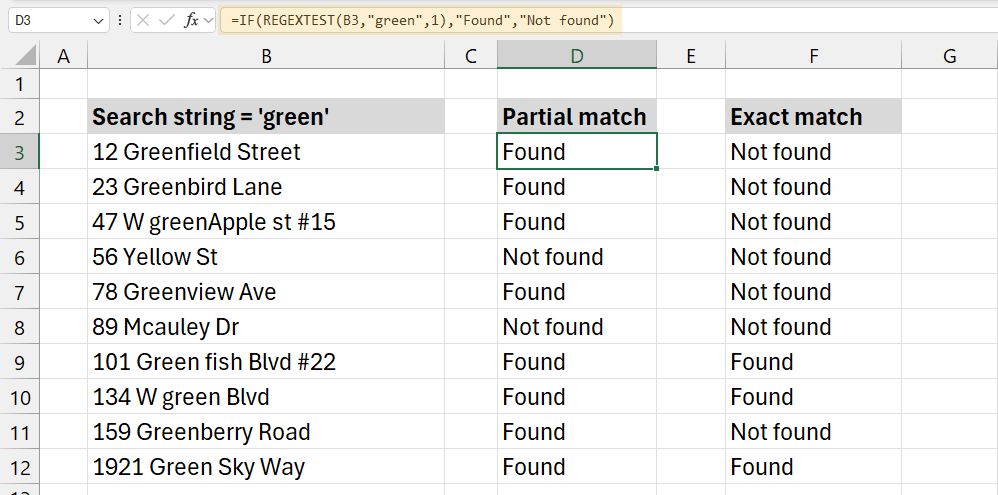
Explanation:
This formula checks whether the word “green” is present in the text within cell B3, regardless of the case (due to return_mode = 1, meaning it’s case-insensitive).
- Regular Expression (“green”): The pattern “green” is the string that the REGEXTEST function looks for in the target cell. Due to the 1 argument in REGEXTEST, the search is case-insensitive.
- Return Mode (1): This argument specifies that the match should be case-insensitive, meaning both “Green” and “green” will be treated as matches.
- IF Statement: The IF function evaluates the result of REGEXTEST. If the result is TRUE (the word “green” is found), the formula returns “Found”. If the result is FALSE (the word is not found), it returns “Not found”.
Example 3: Extract text between two delimiters
We want to extract the text inside parentheses from project descriptions in this example. Using the REGEXEXTRACT function, we can easily isolate and extract the content within the parentheses from each cell.
Formula:
=REGEXEXTRACT(C3,”(([^)]+))”,2)
This formula extracts text enclosed within parentheses from the text in cell C3.
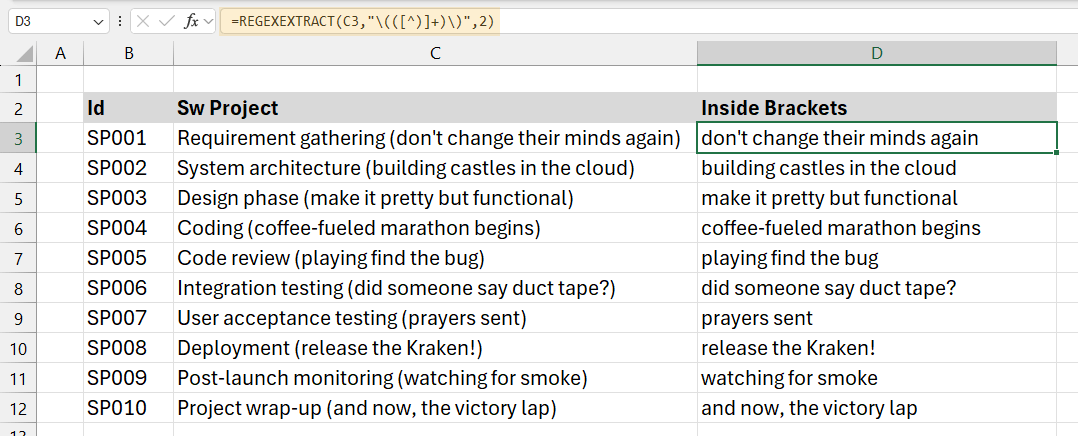
Explanation:
- Regular Expression Pattern (“(([^)]+))”): ( and ): These are literal characters representing the opening ( and closing ) parentheses, which we want to match.
[^)]+: This part of the expression means “match one or more characters that are not closing parentheses.” Essentially, it captures everything inside the parentheses until the closing ). Overall, the pattern searches for any text between an opening ( and closing ). - Return Mode (2): specifies that we want to return the second match in the regular expression pattern. Since there is typically only one set of parentheses per cell in this example, it extracts the content within those parentheses directly.
Example 4: Extract Email from String
In this example, we want to extract email addresses from text strings. The REGEXEXTRACT function allows us to isolate and pull out the email addresses embedded within the text.
Formula:
=REGEXEXTRACT(B3,”\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,}\b”,1)
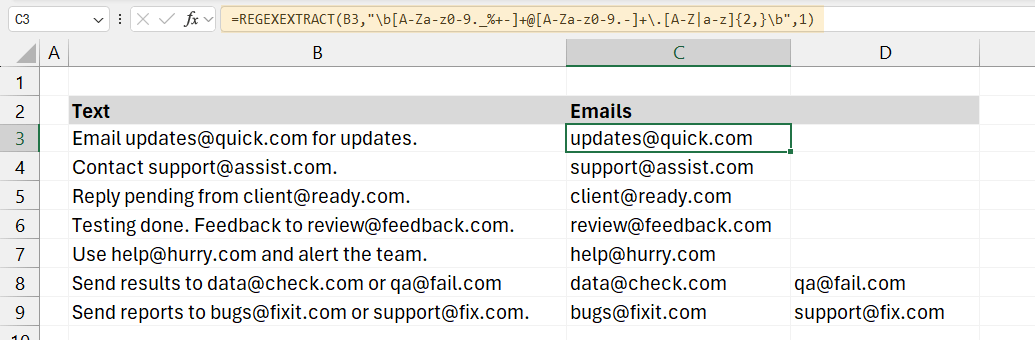
Explanation: Take a closer look at the regular expression pattern!
- \b: This matches a word boundary, ensuring the pattern is treated as a standalone word (in this case, the email address).
- [A-Za-z0-9._%+-]+: This part matches the local part of the email address, which includes letters, numbers, and special characters like dots, underscores, percentage signs, plus signs, and hyphens.
- @: This is a literal character representing the “@” symbol in the email address.
- [A-Za-z0-9.-]+: This matches the domain part of the email address, allowing for letters, numbers, dots, and hyphens.
- .[A-Z|a-z]{2,}: This part matches the top-level domain (e.g., “.com”, “.net”), where {2,} ensures the domain consists of at least two letters.
- \b: This ensures that the match ends at the word boundary (i.e., the end of the email address).
- Return Mode (1): The “1” argument specifies that the function should return the first match it finds. Only the first one is returned if multiple email addresses exist in the text.
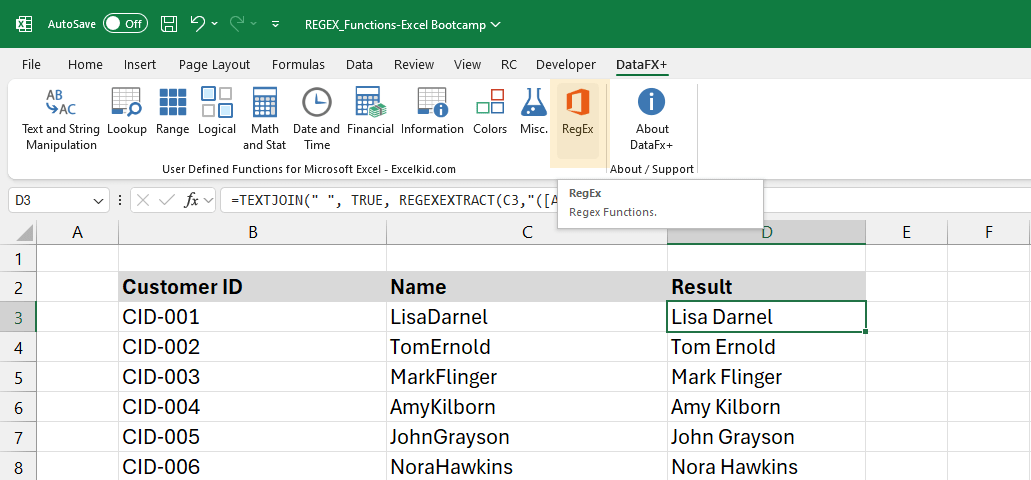
Example 5: Split strings to first and last name
In this example, we aim to separate the first and last names from strings where they are combined without spaces. The formula uses REGEXEXTRACT to identify and extract each name component, and TEXTJOIN combines them with a space. This method helps clean up improperly formatted names quickly.
Formula:
=TEXTJOIN(” “, TRUE, REGEXEXTRACT(C3,”([A-Z][a-z]+)”,1))
This formula splits the first and last names and joins them with a space.
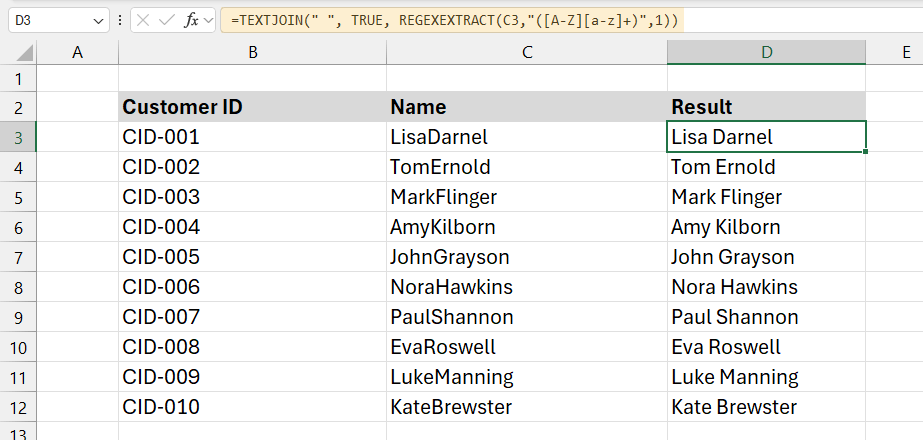
Explanation:
- Regular Expression Pattern: (“([A-Z][a-z]+)”): The pattern captures names that follow this structure.
- [A-Z]: matches the first capital letter of the name.
- [a-z]+: matches the following lowercase letters.
- Return Mode (1): extracts both the first and last name.
- TEXTJOIN combines the two name parts with a space.
- The first argument (” “) specifies that the names should be joined with a space.
- The second argument (TRUE) ensures that empty strings are ignored (though this won’t be an issue here).
- The third argument references the output of REGEXEXTRACT, which provides the extracted names.
In column C, the names appear without spaces (e.g., “LisaDarnel”). The formula in column D converts this into a readable format, such as “Lisa Darnel.”
Example 6: Remove leading zeros
The next example demonstrates how to remove leading zeros from product codes using a combination of REGEXREPLACE and VALUE. Applying this formula lets you quickly clean up product codes or numbers that may have been padded with unnecessary zeros, making the data easier to process and analyze.
Formula:
=VALUE(REGEXREPLACE(B3:B9,”^0+(?!$)”,””))
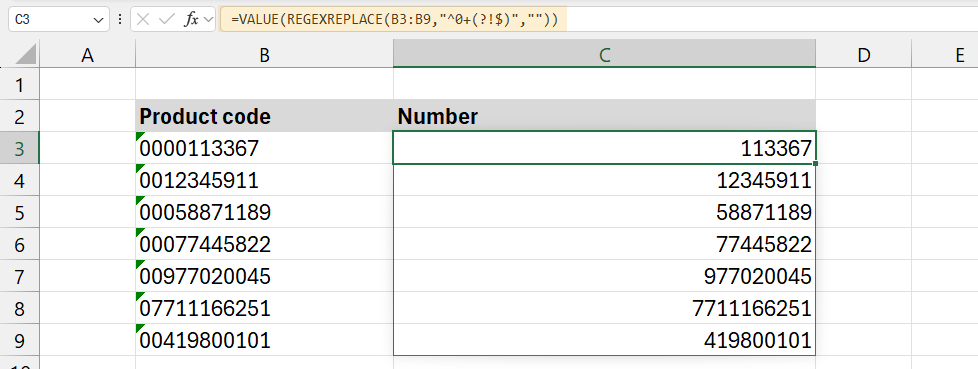
Let us break the formula down!
This function searches for patterns in the text and replaces them with the specified replacement value. Here, it looks for leading zeros and removes them.
- Pattern (“^0+(?!$)”):
- ^: Anchors the match at the beginning of the string, ensuring it only removes zeros at the start.
- 0+: Matches one or more zeros at the start of the string.
- (?!$): Ensures the pattern does not match a string of zeros (like “0000”).
- “” (Replacement): This argument tells Excel to replace the leading zeros with nothing, effectively removing them from the product code.
- VALUE: After removing the leading zeros, VALUE converts the resulting string into a number format. This ensures the data is treated numerically rather than text, allowing for proper calculations and sorting.
Example 7: Extract invoice numbers from text
In this example, we aim to extract 10-character product IDs that begin with “PC” from a cell. Using the REGEXEXTRACT function, we can quickly extract these specific product codes, making it easier to manage and analyze large datasets.
Formula:
=REGEXEXTRACT(B3, “PC\d{8}”)
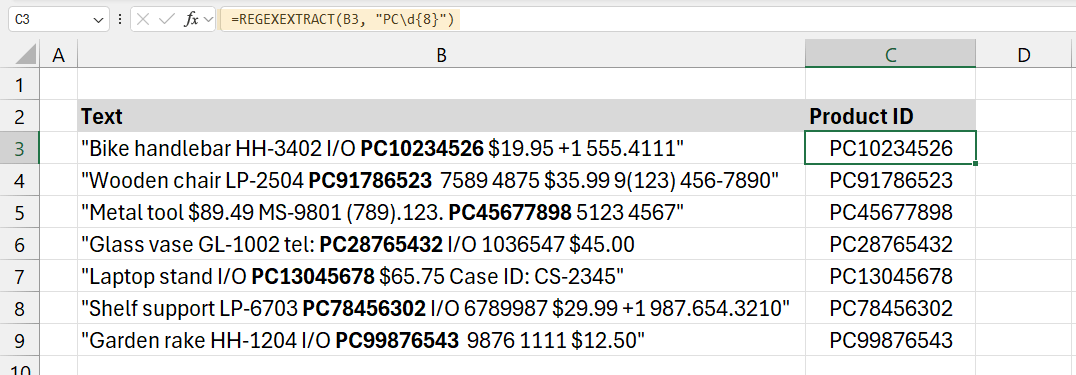
Explanation:
- Pattern (“PC\d{8}”):
- PC: The formula begins by searching for the literal string “PC”, the prefix of our product codes.
- \d{8}: This pattern part matches exactly eight digits. \d represents any digit from 0 to 9, and {8} ensures that exactly eight digits follow “PC”.
Example 8: Get phone numbers from a text
In this example, we want to extract phone numbers from text strings that may contain one or more phone numbers in various formats. Using the REGEXEXTRACT function, we can easily isolate and extract the phone numbers, regardless of whether they are formatted with dashes, parentheses, spaces, or dots.
Formula:
=REGEXEXTRACT(B3, “(?\d{3})?[-.\s]?\d{3}[-.\s]?\d{4}”)
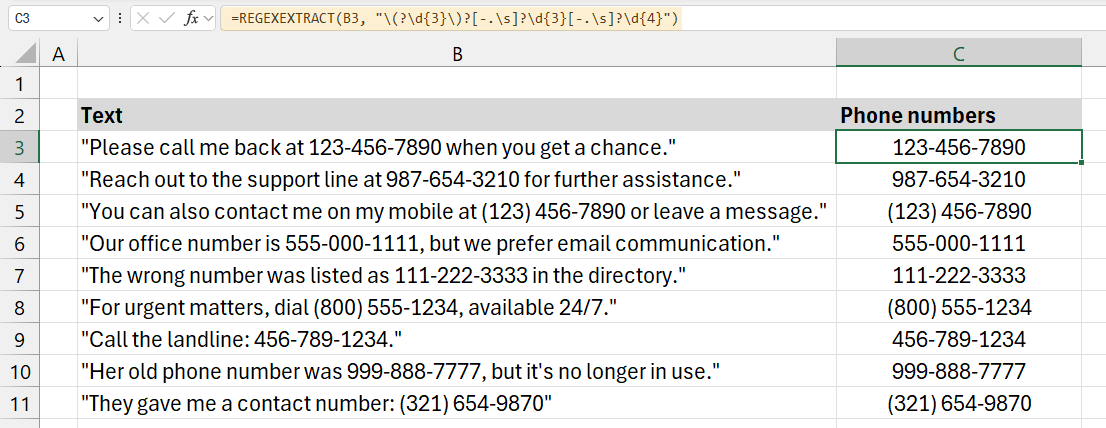
Explanation:
Let’s analyze this pattern: “(?\d{3})?[-.\s]?\d{3}[-.\s]?\d{4}”
- (?: Captures an optional opening parenthesis for the area code, allowing formats like (123).
- \d{3}: Extracts exactly three digits for the area code.
- )?: Identifies an optional closing parenthesis for the area code.
- [-.\s]?: Matches an optional separator (dash, dot, or space) between the area code and the next three digits.
- \d{3}: Retrieves the next set of three digits in the phone number.
- [-.\s]?: Matches another optional separator between the second and third part of the number.
- \d{4}: Extracts the last four digits of the phone number.
Example 9: Hide card numbers
In this example, we use the Excel REGEXREPLACE function to mask sensitive credit card numbers while keeping the format and issuer names intact. The formula dynamically adjusts the number of “X”s based on the card number’s length (15 or 16 digits). It works with various card types, such as Visa, Mastercard, Amex, and Discover.
Formula:
=REGEXREPLACE(B3, “\d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}|\d{4}[-\s]?\d{6}[-\s]?\d{5}”, “XXXX XXXX XXXX XXXX”)
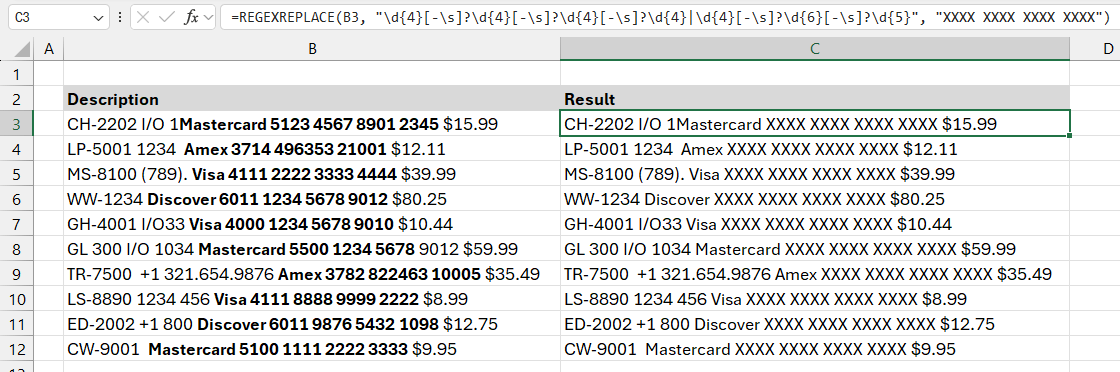
Explanation:
The core function in this formula, REGEXREPLACE, scans the text for patterns that match credit card numbers and replaces those numbers with “X”s, masking sensitive information.
Evaluate the pattern: \d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}|\d{4}[-\s]?\d{6}[-\s]?\d{5}
- \d{4}: Looks for a group of four digits, which is typical in credit card numbers.
- [-\s]?: Accounts for optional separators like dashes (-) or spaces between the digit groups, commonly seen in credit card formatting.
- \d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}: Detects a 16-digit card number format (e.g., Visa, Mastercard, Discover).
- \d{4}[-\s]?\d{6}[-\s]?\d{5}: Captures the 15-digit format typical of American Express cards.
- The pipe (|) symbol ensures that either pattern (16-digit or 15-digit) is recognized.
Replacement text:
- Regardless of the original card format, this replacement will mask the detected card number with the string “XXX XXX XXX XXXX XXXX”. For 15-digit cards like Amex, this will result in slightly more Xs than digits, but it still provides adequate masking.
Regex Cheat Sheet: How to use Regular Expressions in Excel
When crafting regex patterns in Excel, you utilize specific symbols known as ‘tokens’ that correspond with various character types. These tokens simplify the pattern-creation process by representing broad categories of characters rather than individual characters.
- Dot (.): Matches any single character except newline characters. For example, “a.c” matches “abc”, “adc”, and so on.
- Asterisk (*): Matches zero or more occurrences of the preceding element. For instance, “ba” could match “b”, “ba”, “baa”, “baaa”, etc.
- Plus (+): Similar to the asterisk, but requires at least one occurrence of the preceding element. So, “ba+” would match “ba”, “baa”, etc., but not “b”.
- Question Mark (?): Makes the preceding element optional, meaning it can occur at zero or one time. For example, “colo?r” matches both “color” and “color”.
- Caret (^): Used at the start of a pattern to denote the beginning of a line or string. “^A” matches any string that starts with “A”.
- Dollar Sign ($): Placed at the end of a pattern to indicate the end of a line or string. “end$” would match any string that ends with “end”.
- Square Brackets ([ ]): Used to specify a set or range of characters to match. “[abc]” matches “a”, “b”, or “c”. You can specify a range using a hyphen, like “[a-z]” to match any lowercase letter.
- Backslash (): Used as an escape character to allow special characters to be used in patterns. For instance, “\$” would be used to match the dollar sign character itself.
- Pipe (|): Acts as a logical OR operator, allowing you to specify alternative matching patterns. For example, “cat|dog” matches either “cat” or “dog”.
- Parentheses (()): Used for grouping characters or subpatterns. For instance, “(ab)+” matches one or more repetitions of “ab”.
Character classes
Character classes in regular expressions (regex) are special notations used to match any one character from a specific set of characters. They allow you to specify a group of characters you want to match within a text, making your patterns more flexible and powerful.
- Dot (.): This is the most basic character class that matches any single character except for newline characters.
- [abc]: A custom character class matching any character listed inside the square brackets. For example, [abc] matches “a”, “b”, or “c”.
- [^abc]: A negated character class that matches any character not listed inside the square brackets. For instance, [^abc] matches any character except “a”, “b”, or “c”.
- [a-z]: A range character class that matches any single lowercase letter from “a” to “z”. Similarly, [A-Z] matches any uppercase letter, and [0-9] matches any digit from “0” to “9”.
- \d: Matches any digit equivalent to [0-9].
- \D: Matches any non-digit character equivalent to [^0-9].
- \w: Matches any word character, which includes letters, digits, and underscores. It is equivalent to [a-zA-Z0-9_].
- \W: Matches any non-word character, which is anything not included in \w, such as punctuation or spaces. It’s equivalent to [^a-zA-Z0-9_].
- \s: Matches any whitespace character, including spaces, tabs, and line breaks.
- \S: Matches any non-whitespace character.
Anchors
Anchors are special characters that do not match any character themselves but instead assert a position in the text. They specify where a pattern is supposed to start or end within the string. Here are the main types of anchors used in Excel regex:
- Caret (^): This anchor matches the beginning of a string or the beginning of a line in multiline mode. For example, ^Hello matches “Hello” only if it appears at the start of the string.
- Dollar Sign ($): This anchor matches the end of a string or the end of a line in multiline mode. For instance, end$ matches “end” only if it is at the end of the string.
- Word Boundary (\b): This anchor matches a position where a word character is next to a non-word character. It ensures that the characters to be matched are at the beginning, middle, or end of a word. For example, \bword\b matches “word” in “word is the word” but not in “swordfish” or “keywords”.
- Non-word Boundary (\B): This is the opposite of a word boundary. \B matches at positions where there are no word boundaries. This can be useful for matching patterns that should not occur at the beginning or end of words. For instance, \Bain\B matches “ain” in “Spain” and “complaint” but not in “pain” or “main”.
Regex Add-in for Excel
The Regex Add-in for Excel offers a powerful solution for handling complex text patterns, allowing you to search, extract, and manipulate data using regular expressions. Unlike the native regex support available only in Microsoft 365, this add-in works with all versions of Excel, ensuring that you don’t need a 365 subscription to use the benefits of regex.
You can learn more about our add-ins here.